One Step Closer: DeepHouse Architecture
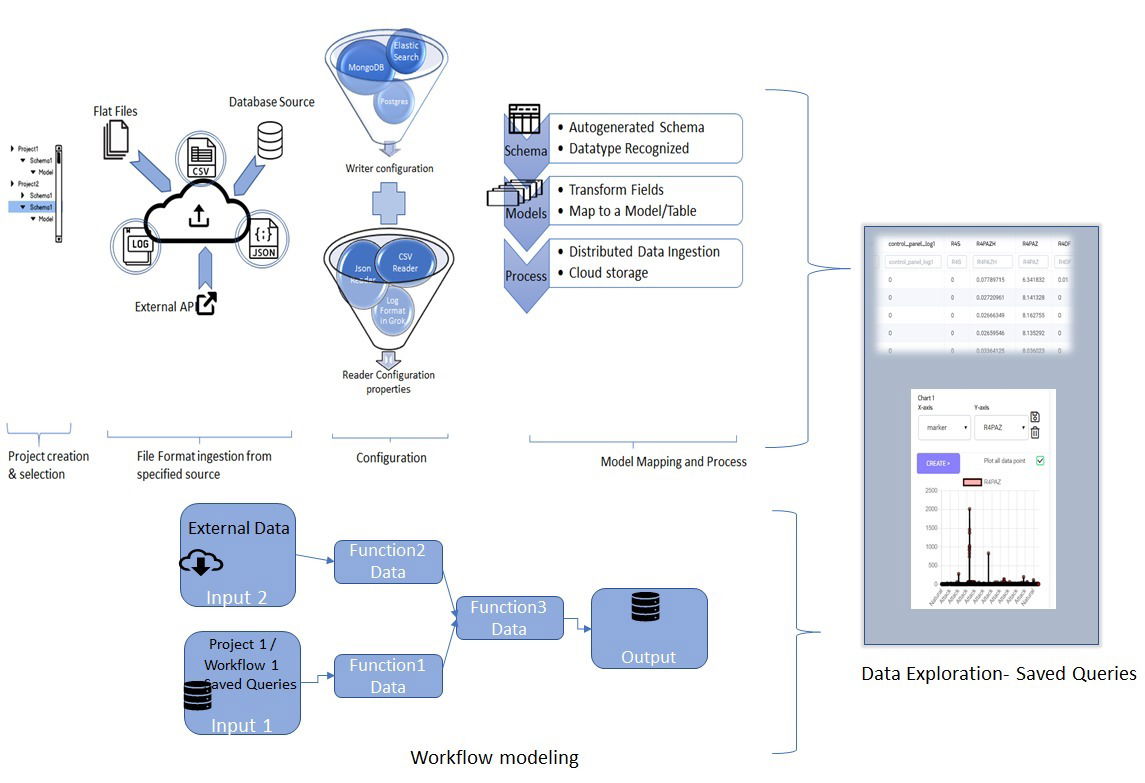 High Level Architecture of DeepHouse Platform
High Level Architecture of DeepHouse Platform
DeepHouse High-Level Architecture:
A quick summary of features of DeepHouse and the typical flow along with sample screenshots. Deephouse Platform is built using microservices paradigm. Summary of features are as follows.
Provides a simplified data ingestion for multiple formats (csv, json and log) and can be extended to other readers easily as loosely coupled entities.
Readers are configurable and compensate for change in formats
Selection of Database/Storage types (Postgres, MongoDB, ElasticSearch)
Configurable Integration with External REST API
Simplified Data Modeling with Autodetection of Schema and Transformation and mapping of the schema into multiple models enabling feature extraction
Automated Ingestion based on the configured schema and models in the project.
Explore ingested data models and plot Charts for quick visualization and helps in the iterative process of modeling
Each saved queries from multiple projects will act as a disparate source that can form input to the Workflow Modeling Module
Workflow Modeling module is a unique feature that enables setting up of tasks/functions as nodes in a Directed Acyclic Graph.
Workflows can be triggered based on scheduling or event-driven
Workflows can form the input to other workflows enabling complex but better organized tasks modeling.
Workflow Tasks can be written in Python or SQL as of Milestone 1.
Project Creation:
Each use-case or data source can be logically separated as “projects”. Snapshot of the existing user interface page that leads the step by step processing flow.
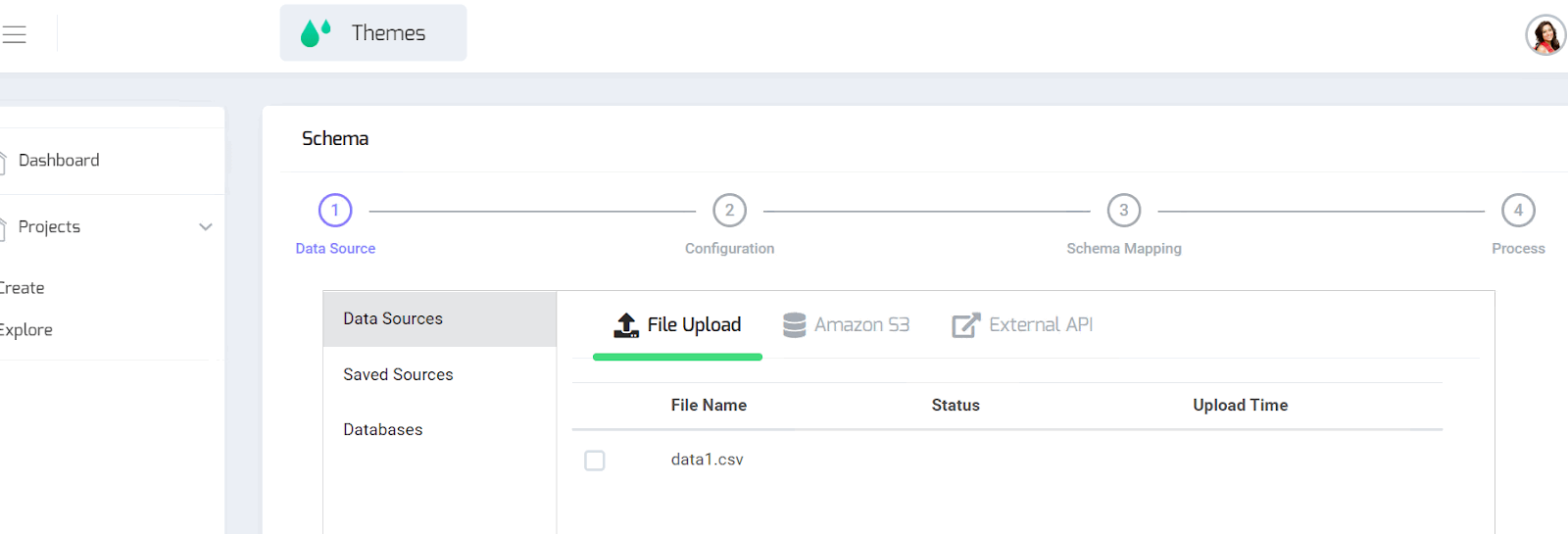
Step 1 : Multi source data ingestion:
From files that can be uploaded, external databases, from External API (currently twitter and Retsly - to be extended)
Step 2: Reader and Writer Configuration
Configurable CSV reader properties such as number of lines to skip, quotes, delimiter, Configurable Log Format - using Grok, Configurable output databases
Step 3: Schema Recognition, Model Mapping and Preview
Automatically retrieves Schema(s) of the files/data records, create mapping to models with custom scripts for each field thus enabling data cleaning and preprocessing
Users can get a preview of 10 rows of data for each mapped model based on a sampled data.
Step 4: Process
Ingestion of the data using scalable distributed processing
Once the above ingestion flow is setup and configured the automation can be turned on to ingest.
Snapshot of DeepHouse Milestone 1 user interface that navigates through initial data modeling process
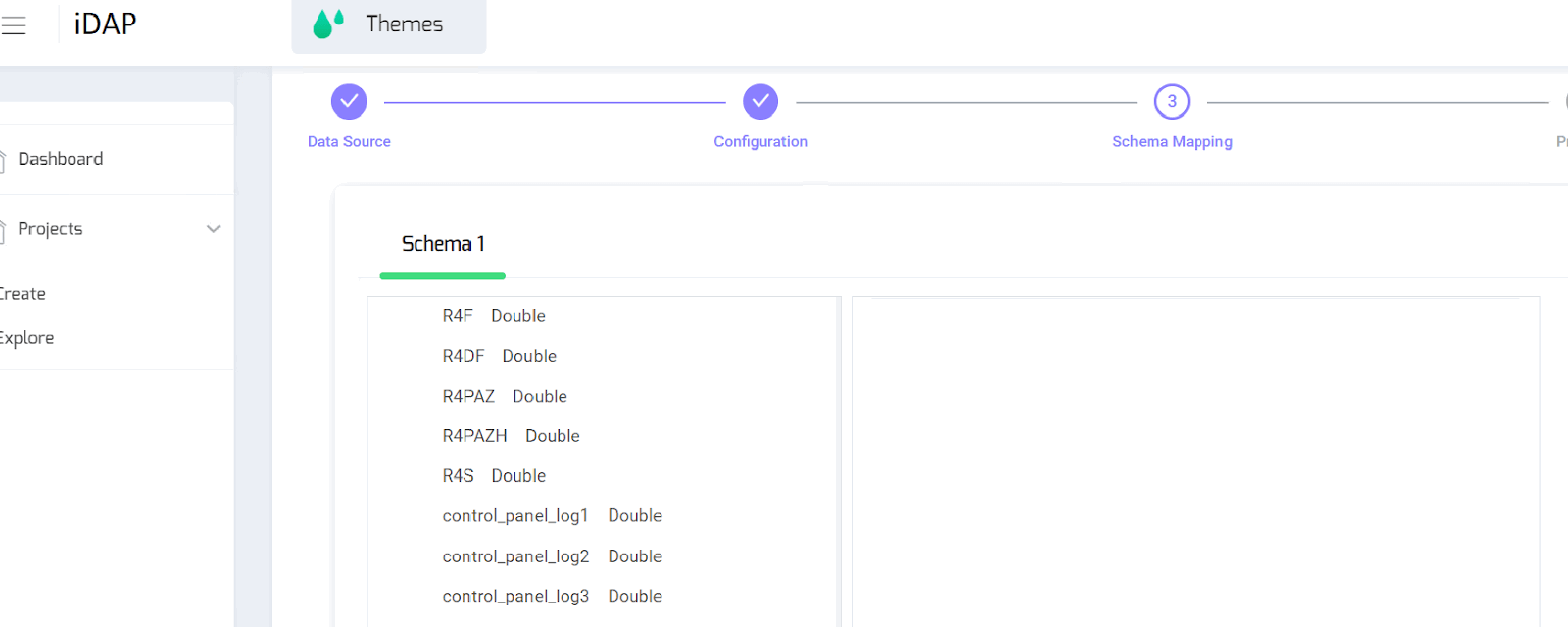
Screenshot of DeepHouse Milestone 1 User interface Schema/model detection and mapping
Explore Data: User can explore the data stored using SQL query, MongoDB or ElasticSearch native query or using language agnostic query to search data. The queries will be saved by default. Under the context of current query and the dataset, X-Y or time series chart can be plotted on the fields in that model.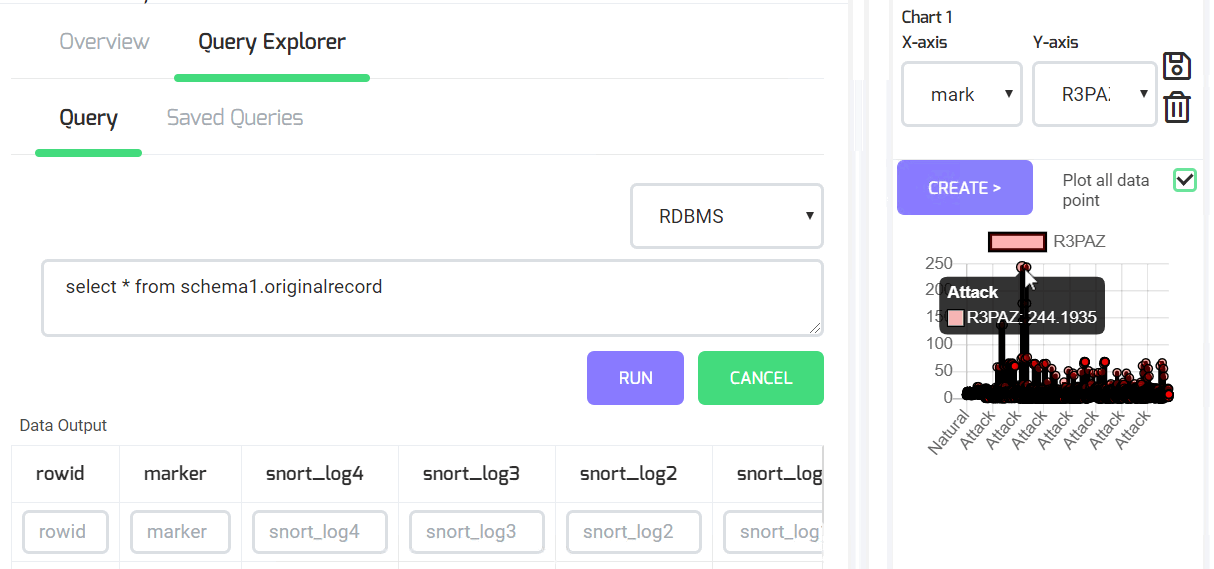
Screenshot Showing Current Ingested Data exploration
Workflow Composer: DeepHouse provides means to run a combination of tasks as a workflow using Directed Acyclic Graph edges representing each task. This enables complex pre-processing and Analytics to be automated and organized.
iDAP : Comparison to other Data Ops Solutions
While researching on a self-service platform for customized data ingestion and complex task modeling, we realized that there is certainly a gap in the industry. Most products in this category cater to ingestion of CSV files and External API integration. They present visualization and transformation capabilities but have very little capability to expand the horizons beyond applications related to search and discovery. This gap has lead us to building a new product using open source components.
